
cb
[논문리뷰] TEVAD 본문
Chen, Weiling, et al. "TEVAD: Improved video anomaly detection with captions." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023.
https://github.com/coranholmes/TEVAD
GitHub - coranholmes/TEVAD: Official implementation for paper TEVAD: Improved video anomaly detection with captions
Official implementation for paper TEVAD: Improved video anomaly detection with captions - coranholmes/TEVAD
github.com
0. Abstract
비디오 감시 시스템은 공중 안전과 개인 자산을 보호하기 위해 사용된다. 그 중에서도 자동 이상 탐지는 인간의 노동을 줄여 주고 그와 관련된 비용을 줄여 줄 수 있다는 장점까지 갖고 있다. 이전 연구들은 오로지 spatial-temporal features를 고려하였지만, 실세계의 복잡한 시나리오에서는 visual feature만으로 semantic한 의미를 모두 담아 높은 정확도를 내기에 어려움이 있다. 따라서 본 논문에서는 Text Empowered Video Anomaly Detection(TEVAD)를 제안한다. 이는 비주얼 정보와 텍스트 정보를 모두 사용하여 이상 탐지를 수행하는 모델로, 비교적 의미가 풍부한 텍스트 피쳐가 비주얼 정보를 보완해 주는 방법을 사용한다. 여기서 텍스트 피쳐는 비디오의 caption(자막) 정보를 사용한다. 해당 방법론은 4개의 밴치마크 데이터셋(ShanhaiTech, UCF-Crime, XD-Violence, UCSD-Redestrians)에서 SOTA 성능을 보였으며 추가적인 알고리즘을 통해 caption 정보의 설명성을 더욱 높일 수 있었다고 한다.
1. Introduction
Video Anomaly Detection(VAD)는 여러 실용적인 적용이 가능하다. 제조업에서는 노동자들의 이상 행동이나 불규칙적인 생산 과정을 detect할 수 있다. 헬스 케어에서는 환자의 상태를 모니터링하고 사고가 일어났을 때 알람을 울려 주는 등 간호사들의 작업량을 줄여줄 수 있다. 공중 안전과 관련된 경우에는 싸움이나 총기 난사 등 불법적인 행동을 탐지하여 즉시 경찰에 신고되게 하여 개인적인, 자산적인 손실을 줄여 줄 수 있다.
하지만, 이런 다양한 적용이 가능함에도 불구하고 비디오 이상 탐지라는 태스크는 훈련 데이터의 불균형으로 인해 학습하기 조금 까다롭다는 단점이 있다. 보통 긴 영상 중에서 “이상”에 해당하는 부분은 짧게 일어나고, 불규칙적으로 일어난다. 또, 이상 상황이라는 것은 몇 가지로 특정되어 있는 것이 아니라 다양하게 일어날 수 있기 때문에 만약 학습 과정에서 배우지 못한 이상(anomal)인 경우에는 그를 탐지하기 어렵다는 단점이 있다. 또, 이상이라는 것의 기준 자체가 모호하기 때문에 비디오 이상 탐지 태스크에는 항상 불확실성이 따른다.
그렇지만 비디오 이상 탐지의 넓은 활용력 덕분에 해당 분야에서 많은 연구가 이루어졌다. 보통 spatial-temporal visual feature를 사용하여(TSN, C3D, I3D 등) 비디오의 이상을 탐지했다. 하지만 단순히 비주얼 정보만 사용한 방법론 자체는 high-level의 semantic meanings를 담아내기에는 어려움이 존재했고, 복잡한 시나리오에 일반화하기 어렵다는 단점이 있었다. 단순히 이상 점수(anomaly socres)만 사용해서 이상을 탐지했다는 문제점도 존재했다.
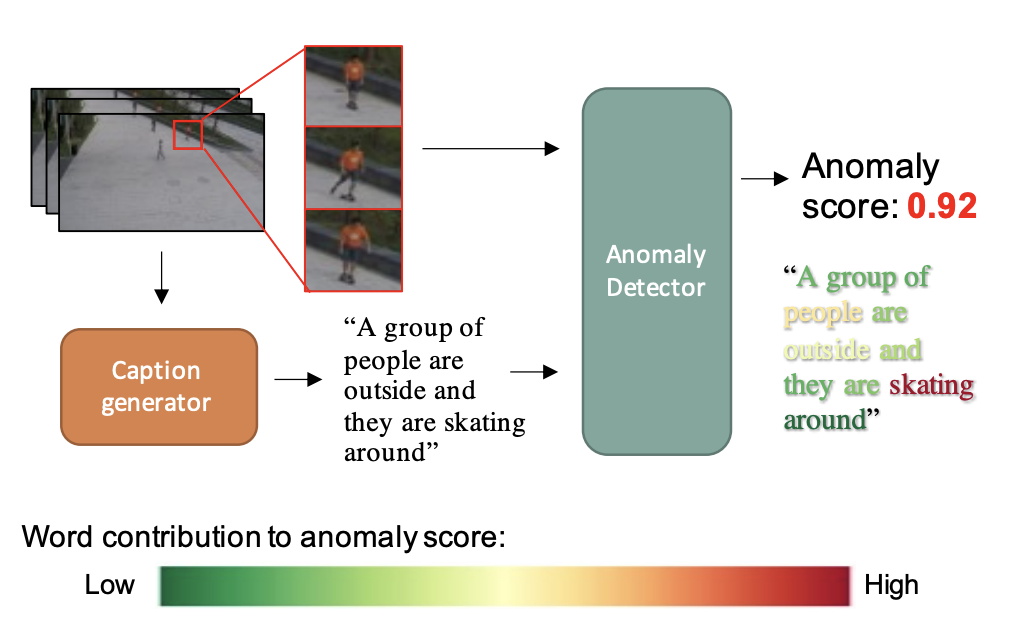
따라서 본 논문에서는 영상의 semantic한 정보도 모두 담을 수 있는 pretrained LLM 모델로 captioning을 진행하여 정확도와 robustness를 모두 보장할 수 있는 방법을 VAD 방법을 제안한다. 이는 최근의 LLM 모델이 text-video 쌍을 사용하여 높은 정확도의 captioning을 수행하고 있으며 symbolic representation을 풍부하게 담고 있기 때문에 가능할 것이다.
이를 위해 해당 실험에서는 먼저 비디오를 작은 단위(short snippets)로 나누고, 각 단위에 대해 자막을 생성한다.(generate the dense captions for these snippets) 이렇게 만들어진 자막 피쳐들은 visual features과 결합(fused)되어 비디오의 이상을 탐지하기 위한 최종 이상 점수(anomaly score)를 계산하게 된다.
결론적으로 이들이 주장하는 논문의 기여는 다음과 같다
- 본 논문에서는 visual와 text feature를 모두 담아 비디오 이상 참지를 수행하는 multi-modal 방법, TEVAD를 제안한다.
- 이들은 multi-scale temporal learning을 text feature로 확장하여 snippet features의 dependencies를 더욱 잘 포착할 수 있도록 하였다.
- 해당 프레임워크는 4개의 벤치마크에서 SOTA를 달성하였고, robustness를 향상시킬 수 있었다.
- 또한, word-masking protocol을 사용하여 이상 비디오의 설명력을 높였다는 추가적인 분석까지 제공한다.
2. Related Work
2.1 Image anomaly detection using captions
아마 이 논문이 video anomaly detection task에 captions을 적용한 첫 논문이라고 한다… image anomaly detection 분야에서는 그래도 caption을 사용한 몇 실험이 있었는데, 거기서는 DenseCap이라는 모델을 사용해서 캡션을 생성했다고 함. 이미지 피쳐는 CNN을 사용해서 추출하였고 Caption based feature는 Word2Vec을 사용. 두 개의 임베딩을 concatenate해서 unsupervised anomaly detection을 진행했다고 한다. 최근에는 CLIP을 사용해서 zero-shot 학습을 진행했다고 하지만 실세계 시나리오에서 normal과 abnormal이 구체적으로 정의되지 않아 한계가 있었다고 함.
2.2 Video anomaly dectetion using visual features
video에서 anomaly detection은 학습 과정 중의 supervision에 따라 몇 가지로 분류될 수 있다고 한다. unsupervised learning, weakly-supervised learning, 등등…은 다른 자료를 찾아 보면 쉽게 나올 것.
2.3 Video captioning
video captioning은 video understanding의 아주 중요한 과제로 분류됨. object level representations를 배우기 위해 다양한 노력들이 있었고, 최근에는 transformer models를 통해 여러 downstream에 적용되고 있다고 함.~~
3. Our method
우선, 아래는 TEVAD(Text Empowered Video Anomaly Detection)의 전체적인 프레임워크를 나타낸 것이다.
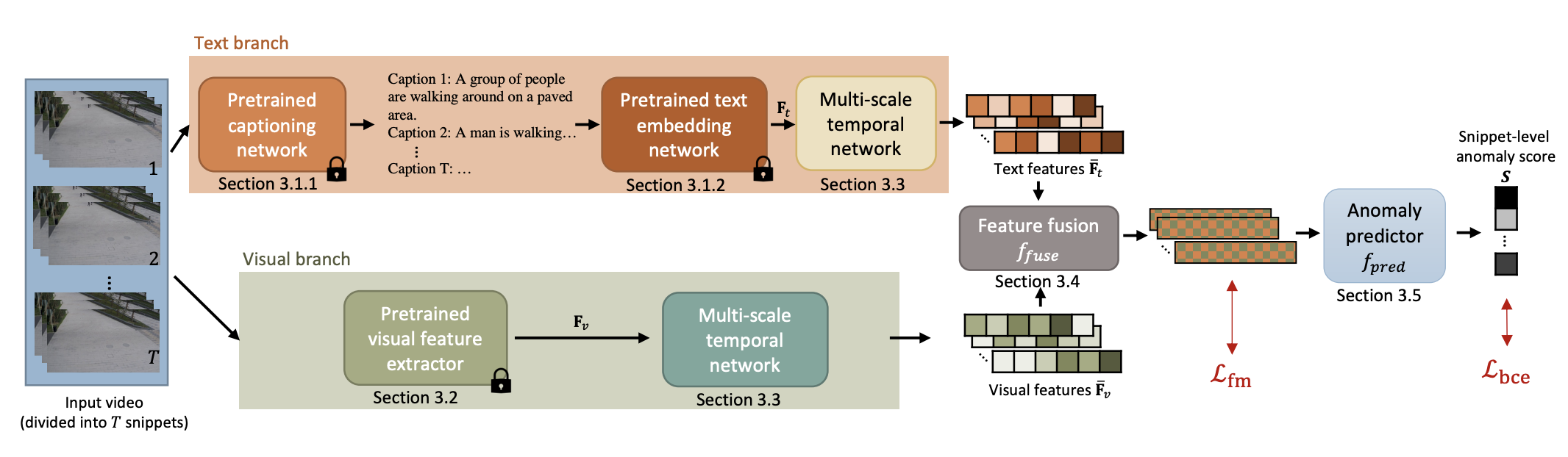
우선 비디오 V를 받으면 TEVAD는 비디오를 T개의 snippets, v로 분할한다. 그런 다음 학습은 두 개의 branch로 나누어져 각 snippets를 병렬적으로 처리하게 된다. 먼저 text branch에서는 dense captions를 생성하고 text feature (sentence embedding)을 추출하고 visual branch에서는 visual I3D feature를 추출해낸다. 여기서 multi-scale temporal network는 두 branch 모두에 포함되어 있어 multi-scale temporal dependencies를 잘 잡아낼 수 있다. multi-scale visual의 결과인 $F_{vis}$, multi-scale text의 결과인 $F_{txt}$은 함께 합쳐지고 feature magnitude를 계산하는 데에 사용이 된다. 여기서 가장 높은 K개의 점수를 가지는 feature들은 binary snippet classifier로 넘어가고(이때 normal이든 abnormal이든 모두 classifier에 넘어간다), snippet 레벨의 prediction이 수행된다.
3.1 Generating text features for videos
3.1.1 Generating dense captions for videos
기존의 여러 연구들에서 비디오의 dense captions를 생성해냈지만, 이들은 single caption generation 모델에 비해 충분한 성능을 보이지 못 했다. 특히, dense caption model들은 important events를 결정하는 데에 어려움이 있었다고 한다.
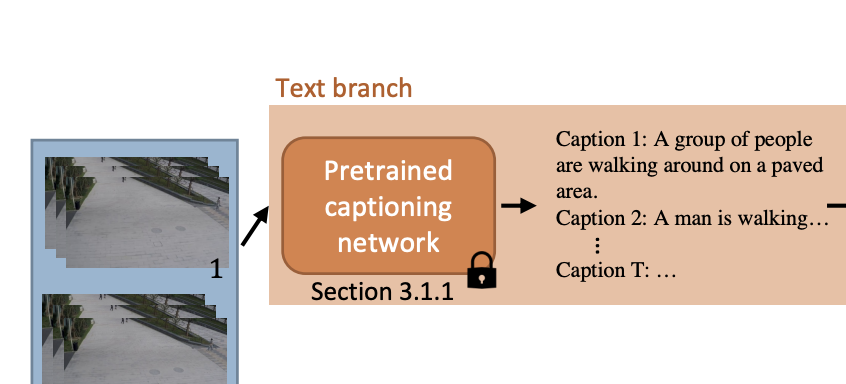
이런 관점에서, 본 논문에서는 single caption models를 사용하여 text features를 생성해냈다고 한다. 뒤에서 visual feature와 text feature를 통합하기 위해 각 snippet 단위로 caption을 생성해내기로 했다. 하지만 각 snippet은 비디오의 captions을 생성해내기엔 너무 적은 frame을 포함하고 있었다. 따라서 여기서는 sliding window strategy를 사용해서 16개 프레임마다 연속된 64개 프레임에 대한 caption을 생성해냈다고 한다. 비록 sliding window strategy는 중복되는 정보를 인코딩하긴 하지만, information loss를 줄이는 장점이 있었고 important event를 보존할 수 있는 장점이 있었다고 한다.
해당 과정에서 사용한 video captioning 모델은 SwinBERT이고, 여기서(Text branch)는 Video Swin Transformer를 사용해 visual features를 추출할 수 있다고 한다. visual branch에서는 I3D를 사용하여 visual feature를 추출하기 때문에, 두 가지의 다른 네트워크를 사용함으로써 서로 다른 representation을 활용할 수 있었고, 이상 탐지의 performance를 향상시킬 수 있었다고 한다.
caption을 생성하기 위해 이들은 MSVD, VATEX, TVC라는 video captioning 데이터셋을 사용하였는데, 이는 기존의 이상 탐지 데이터셋에서 captioning 모델을 훈련시키기에 필수적인 캡션들을 포함하지 않았기 때문이라고 한다. 그렇기 때문에 captions가 비디오의 content를 정확하게 반영하진 않지만 이런 부정확한 captions에도 불구하고 이상 탐지를 잘 수행해 냈다고 한다. ..
3.1.2 Generating sentence embeddings for videos
생성된 비디오 captions로부터 text features를 만들어내기 위해 본 연구에서는 SimCSE를 사용하여 문장 임베딩을 생성해냈다. 이는 contrastive learning을 사용하여 문장 임베딩을 생성해내는 모델인데, dropout noise를 줄이고 annotated pairs를 통합함으로써 그를 가능하게 했다고 한다.
TEVAD의 프레임워크는 개별 component를 유연하게 다룰 수 있고, SimCSE는 최소한의 조정으로 다른 SOTA sentence embedding 모델로 대체될 수 있다고 한다. 다른 모델로 대체하기 쉬워서 모델을 바꿔버려도 무방하다는 뜻인가?…
3. 2 Generating Visual features for videos
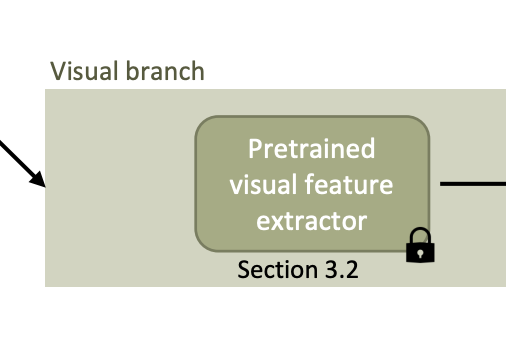
해당 부분에서는 ResNet-50를 백본으로 사용한 I3D 모델을 사용하여 visual features를 추출해낸다. 다른 관련 연구와 동일하게 여기서는 ten-crop이나 five-crop을 사용하여 data augmentation을 수행하였다고 한다. five-crop의 경우에는 프레임을 입력받았을 때 4개의 모서리와 센터로 프레임을 크롭하였고, ten-crop의 경우에는 five-crop을 수평으로 나누어 진행하였다고 한다.
제안된 프레임워크에서 I3D는 C3D, TSN을 포함한 다른 feature extractors로 대체하여 사용이 가능하다. 몇 가지 실험을 통해 I3D가 가장 높은 성능을 보였기 때문에 해당 실험에서는 우선 I3D feature를 사용하여 실험을 진행하였다고 한다.
3.3 Multi-scale temporal feature learning
Multi-scale Temporal Network(MTN)은 각 snippet별 visual features들의 길고 짧은 범위의 temporal dependencies를 포착하기 위해 다른 연구에서 먼저 제안된 것이라고 한다. 본 연구에서는 MTN을 text feature에도 사용하고 visual feature에 통합함으로써 성능을 향상시킬 수 있었다고 한다.
visual MTN과 유사하게, text MTN도 3-layer pyramid dilated convolutions(PDC) 블록을 포함하고, **non-local 블록(NLB)**을 가진다고 한다. 시간 범위에 따른 PDC는 multi-scale representation을 학습하는 데에 사용되고, NLB는 글로벌한 temporal dependencies를 학습하는 데에 사용된다.
두 블록의 출력은 concatenated되고 원래의 feature에 합쳐져 최종 출력인 $\bar{F_{txt}}$을 생산해낸다. 비슷한 과정을 통해 $\bar{F_{vis}}$도 출력된다. MTN 과정을 visual, text features 모두에 적용함으로써 TEVAD는 두 모달리티에 대한 temporal dependencies를 배울 수 있게 되었다고 한다.
3.4 Multi-modal feature fusion
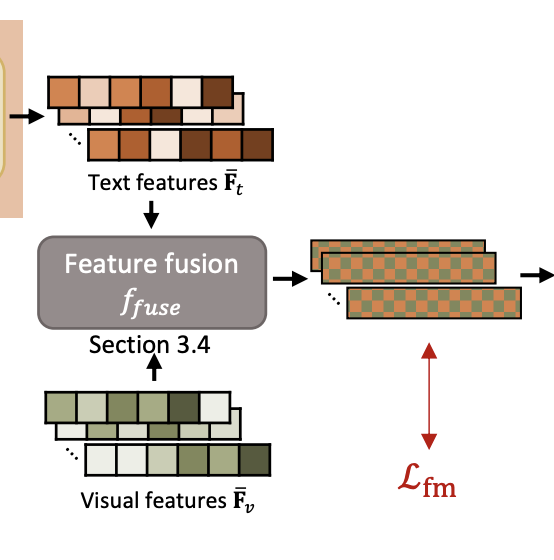
MTN의 출력을 얻고 나면, late fusion scheme을 통해 각 피쳐를 통합한다. 본 연구에서는 concatenation, addition, product 모두를 진행해 보았다고 한다. 각 visual feature가 5/10개로 크롭되었기 때문에 각 text feature들이 visual feaure 각각에 대응되게 배치되어야 한다고 한다.
(a) concatenation: 그냥 바로 $\bar{F_{txt}}와 \bar{F_{vis}}$ 를 이어 붙여 $X= \{\bar{F_{vis}}|\bar{F_{txt}}\}$ 를 구성힘
(b) addition: element-wise addition을 수행했는데, vis의 차원이 txt의 차원보다 크기 때문에 fc layer를 통해 visual feature의 차원을 text feature의 차원에 맞추어 줄여 주었다고 한다. 최종적으로, $X = f_{FC}(\bar{F_{vis}};δ)+\bar{F_{txt}}$를 구성하게 되고, δ는 fc layer의 weight들을 의미한다.
(c) product: Hadamard product를 수행하였다고 한다. addition 과정과 비슷하게, fc layer를 사용하여 차원을 맞춰 주고, $X = f_{FC}(\bar{F_{vis}};δ)⊙\bar{F_{txt}}$를 수행하여 X를 생성한다.
결과적으로, 여기서는 만들어낸 fused feature $X$를 3개의 fc layer에 통과 시켜 anomaly scores를 계산한다고 한다.
3.5 Model training
Training 동안에 모델은 video level label에만 접근이 가능하다고 한다. abnoraml 분할들은 noraml 분할들보다 더 큰 feature magnitude를 가지도록 학습된다. 그 과정에서 L2 norm을 사용하고, 아래의 식을 통해 feature magnitude가 계산된다.
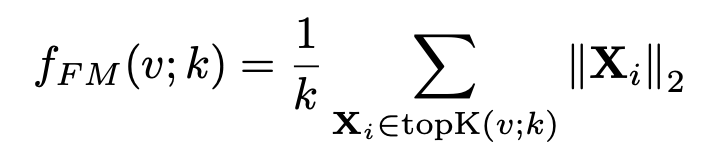
학습의 목적은 보통의 영상(normal video)과 이상 영상(abnormal video)의 anomaly score 차이를 최대화하는 것이다. 그렇기 때문에 loss는 아래와 같이 계산된다. c는 사전에 미리 정의된 상수값이고, |v|는 training set 안의 비디오 개수를 의미한다.
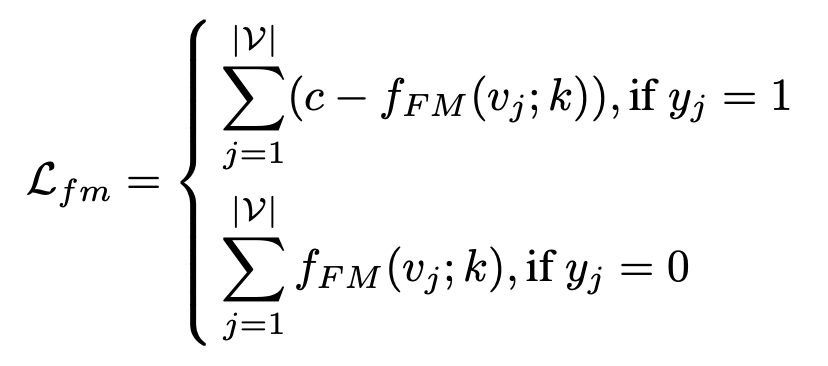
선택된 Top-k snippet의 anomaly score은 아래의 식을 통해 계산되고,
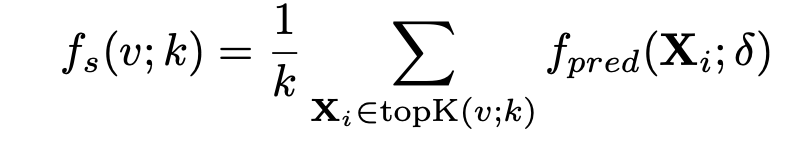
실제 anomaly detection에서는 아래의 binary cross entropy loss를 통해 binary classifier를 학습시킨다.
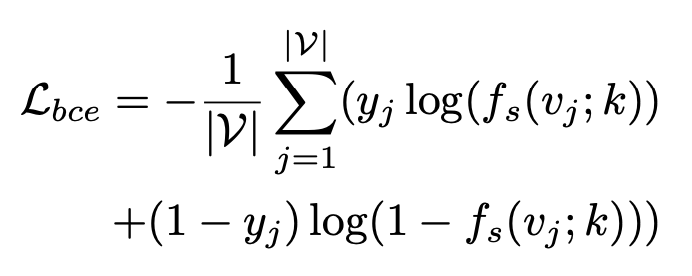
최종적으로, 본 학습에서 사용하는 loss function은 fm Loss와 bce Loss를 합한 아래의 식으로 표현된다.
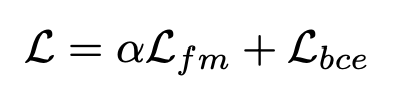
4. Experimental results
4.1 Datasets and evaluation metrics
TBA…….
'ai - paper' 카테고리의 다른 글
| [논문 리뷰] PFMF (0) | 2024.10.18 |
|---|---|
| [논문리뷰] I-JEPA (1) | 2024.10.01 |
| [논문리뷰] One-2-3-45 (1) | 2024.09.28 |
| [논문리뷰] Pix2Pix (0) | 2024.09.28 |
| [논문 리뷰] VoxelNet (0) | 2024.08.08 |



