Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture
Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, Nicolas Ballas
https://arxiv.org/pdf/2301.08243
Abstract
본 논문에서는 hand-crafted data-augmentations에 의존하지 않고 highly semantic image representations을 학습하는 방법, I-JEPA(Image-based Joint-Embedding Predictive Architecture)을 제안.
이는 이미지의 self-supervised learning을 위한 비생성형(non-generative) 방법론을 사용함. : 단일 context block에서 다양한 target block의 표현을 예측하는 것
(a) 샘플 타겟 블록이 충분히 커야 하고, (b) 충분히 의미있는 context block을 사용하는 것이 중요.
Introduction
- CV에서 self-supervised learning
- invariance-based pre-training methods
- encoder를 최적화하여 같은 이미지에 대한 여러 view들의 embedding을 비슷하게 출력하도록 하는 방법. 이는 hand-crafted data augmentation이 사용됨
- high semantic level의 표현을 생성해 낼 수는 있지만, downstream task에 적용할 때 pretraining task의 bias를 포함하고 있을 확률이 높음
- image classification, image segmentation이 다른 invariances를 요구하는 것이 그 예
- 다른 모달리티로 일반화하는 것에도 어려움
- generative methods
- cognitive learning) internal model에 sensory input responses를 예측하기 위해 biologycal systems의 representation learning을 적용한 것
- input의 오염된 부분을 없애고, 오염된 부분이 원래 어떤 건지 예측하는 것.
- mask-denoising이 그 예
- 그러나, 결과가 lower semantic level을 보이고, invariacne-based pretraining in off-the-sheld evaluations(linear probing)
- invariance-based pre-training methods
- 따라서 본 연구에서는 추가적인 prior knowledge 없이고 semantic level을 높일 수 있는 방법을 찾아냄. (joint-embedding predictive architecture)
- abstract representation space에서 missing information을 찾아내야 함
- single context block이 주어지면 한 이미지 내에서 다양한 target block을 사용하여 representation을 예측하는 것. (target representations는 학습된 target-encoder 네트워크를 사용하여 추출)
- pixel/token space를 예측하는 생성형 방법과는 다르게, I-JEPA는 불필요한 픽셀 디테일이 제거된 abstract prediction targets를 활용함으로써 더 많은 semantic features를 학습할 수 있음.
- 또, semantic representations는 multi-block masking strategy를 사용하여 만들었다고 함

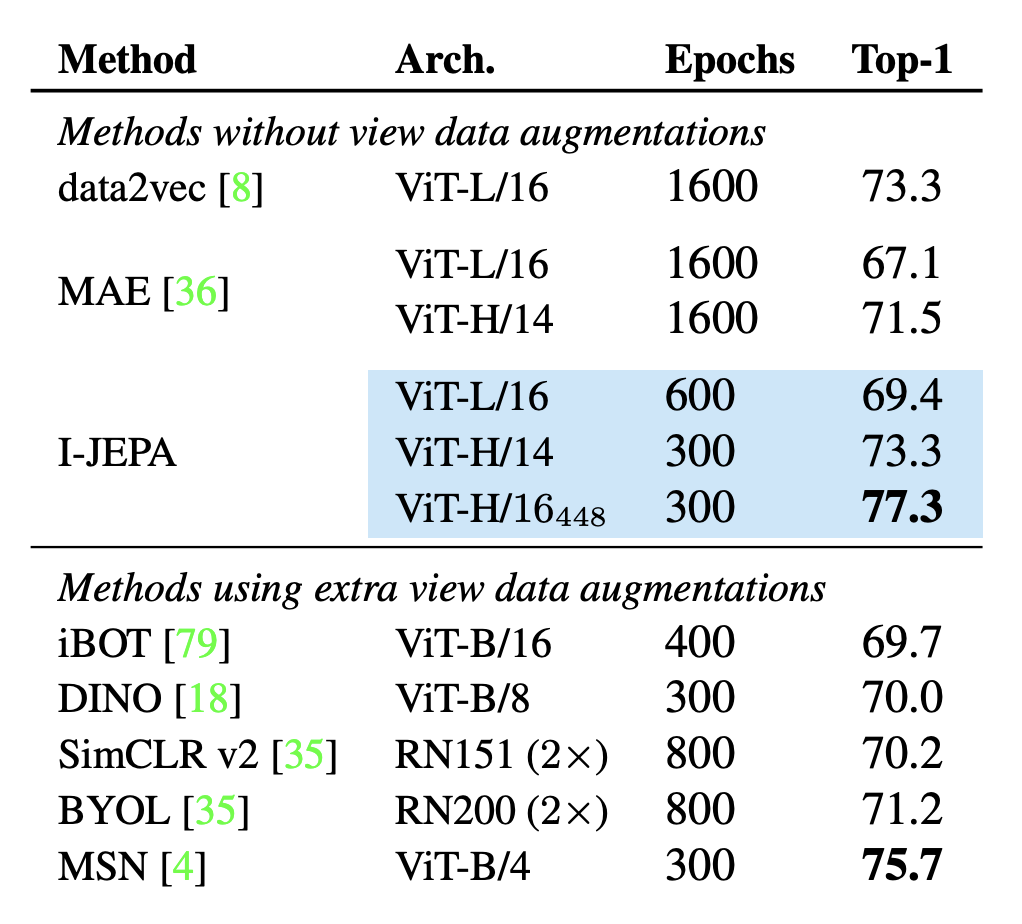
뭐… 보다시피 view data augmentations 없이도 다른 애들보다 성능이 좋았다네요?
Background

compatible inputs x, y에 대해 비슷한 embedding을 내도록, incompatible inputs에 대해서는 비슷하지 않은 embedding을 내도록
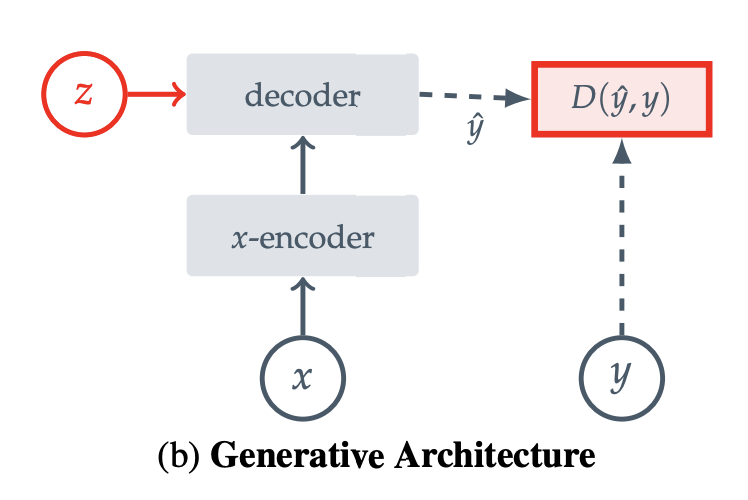
compatible signal x에서 signal y를 reconstruction. (decoder를 사용해서)
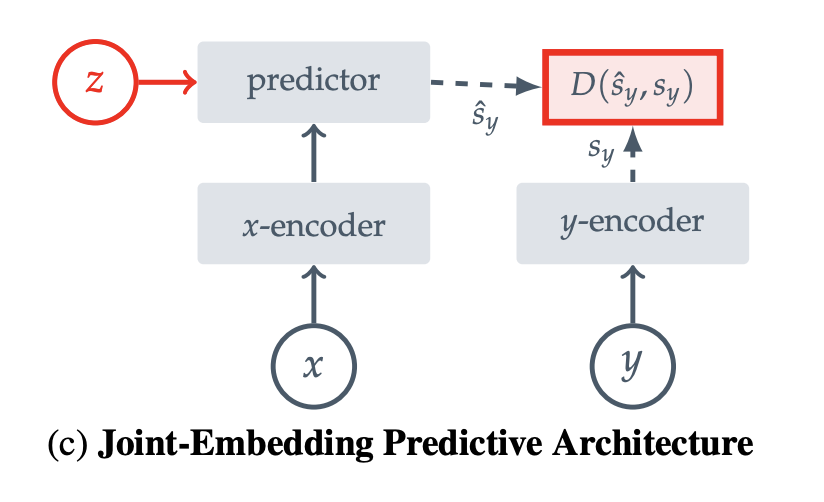
compatible signal x에서 signal y의 embedding을 예측하기 위해 predictor network를 사용함. (prediction을 facilitate하기 위해 z에서부터 시작.)
Method

context block이 주어지면, 한 이미지에 대한 다양한 target blocks를 예측
ViT를 사용하여 context encoding, target encoding, predicting을 진행 (self-attention, FC MLP)
Targets
타겟 이미지들은 이미지 블록의 representation에 대응된다. 이미지 y를 주면, 이는 N개의 non-overlapping patches로 변환되고, 타겟 인코더를 지나 패치 레벨의 표현 $s_y$를 얻게 된다.
여기서 일반적으로 (0.15,1.5) 범위의 랜덤 종횡비와 (0.15,0.2) 범위의 랜덤 크기로 블록을 샘플링한다.
Context
단일 context block에서 target block의 representation을 예측해야 하므로, 이미지에서 랜덤한 크기의 블록 x를 먼저 생성해 낸다. 여기서 context block x와 연관된 마스크를 $B_x$라고 하고 i번째 블록의 마스크를 $B_i$라고 한다.

Prediction
컨텍스트 인코더의 출력이 주어지면 타겟 마스크에 해당하는 타겟 블록에 대해 predictor는 context encoder의 출력과 각 패치의 마스크 토른을 입력으로 사용한다.
Loss

예측된 패치 레벨의 representation $\^s_y(i)$ 과 타겟 representation $s_y(i)$의 L2 loss

Experiments

'ai - paper' 카테고리의 다른 글
| [논문 리뷰] PFMF (0) | 2024.10.18 |
|---|---|
| [논문리뷰] TEVAD (6) | 2024.10.02 |
| [논문리뷰] One-2-3-45 (1) | 2024.09.28 |
| [논문리뷰] Pix2Pix (0) | 2024.09.28 |
| [논문 리뷰] VoxelNet (0) | 2024.08.08 |