본 게시물은 <Do It! BERT와 GPT로 배우는 자연어 처리>의 6장을 보고 정리한 글입니다. 실습에서 사용되는 오픈소스 패키지는 아래의 링크를 참고하시길 바랍니다
https://github.com/ratsgo/ratsnlp
GitHub - ratsgo/ratsnlp: tools for Natural Language Processing
tools for Natural Language Processing. Contribute to ratsgo/ratsnlp development by creating an account on GitHub.
github.com
개체명 인식(named entity recodnition)
개체명 인식이란 문장을 토큰화한 뒤 토큰 각각에 인명, 지명, 기관명 등 개체명 태그를 붙여 주는 과제이다. 그 예시로, 아래와 같이 '그 제품 삼성 건가요?'라는 입력 문장이 있을 때, '삼성'에 기관명이라는 태그를 붙여 줄 수 있다.

본 교재에서는 이번 실습의 데이터로 한국해양대학교 자연언어처리연구실에서 공개한 데이터를 사용한다. 여기에 윤주성님이 개발한 BERT기반 개체명 인식 모델로 초벌 레이블링을 수행한 뒤 수작업으로 해당 레이블이 맞는지 검토한 데이터까지 추가로 포함하였다.
개체명 태그 수와 종류는 데이터를 제작할 때 자유롭게 정할 수 있지만, 이번 실습에서는 한국해양대학교 데이터셋의 태그 체계를 따른다. 그 종류는 아래와 같다.

우리가 만들 개체명 인식 모델의 입력은 토큰 시퀀스이다. 앞의 예를 기준으로 설명한다면 [그, 제품, 삼성, 건가요]가 된다. 이 모델의 출력은 각 토큰이 어떤 개체명 태그에 속할지 확률을 나타낸다.
확률은 아래와 같은 순서로 나타난다.

모델 구조
이 책에서 사용하는 개체명 인식 모델은 다음 그림과 같은 구조이다. 입력 문장을 토큰화한 뒤 문장 시작과 끝을 알리는 CLS와 SEP를 각각 원래 토큰 시퀀스 앞뒤에 붙인다. 이를 BERT 모델에 입력하고 모든 토큰에 대해 출력을 뽑는다.

태스크 모듈
개체명 인식 모델에 붙는 태스크 모듈은 아래와 같다. 우선 마지막 레이어의 개별 토큰 벡터에 드롭아웃을 적용한다. 그 다음 개별 토큰 각각에 가중치 행렬을 곱해 개별 토큰 벡터 각각을 분류해야 할 범주 수만큼의 차원을 갖는 벡터로 변환한다. 만일 토큰 벡터 하나가 768차원이고 분류 대상 범주 수가 11개(개체명 태그 10개 범주 + '개체명 아님' 범주)라면 가중치 행렬 크기는 768*11이 된다.
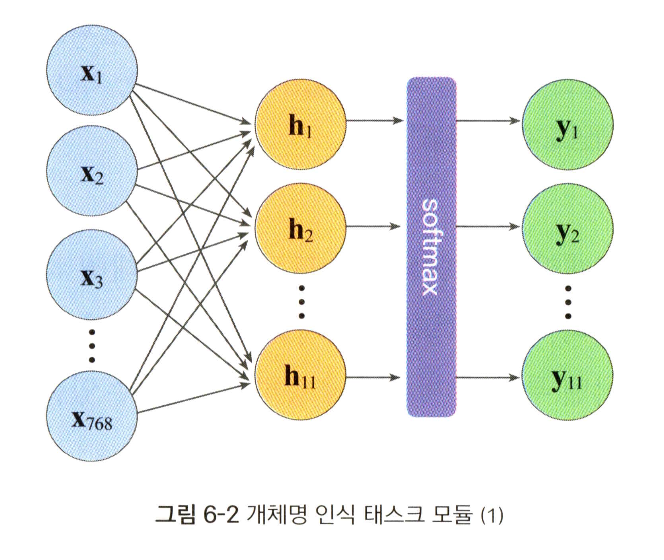
다만 개체명 인식 모델은 토큰 각각을 개체명 확률로 내어 주므로 실제로는 다음과 같은 구조가 된다. 이렇게 만든 모델의 최종 출력과 정답 레이블을 비교해 모델 출력이 정답 레이블과 최대한 같아지도록 BERT 레이어 전체를 포함한 모델 전체를 업데이트한다.

개체명 인식 모델 학습하기
'ai - study' 카테고리의 다른 글
| [3D Vision] Image Formation 강의 정리 (3) | 2024.08.08 |
|---|---|
| [Do It! 자연어 처리] Chapter 05 - 문장 쌍 분류하기 (0) | 2024.04.08 |
| [Do It! 자연어 처리] Chapter 04 - 문서에 꼬리표 달기 (0) | 2024.04.03 |
| [Do It! 자연어 처리] Chapter 03 - 숫자 세계로 떠난 자연어 下 (0) | 2024.04.01 |
| [Do It! 자연어 처리] Chapter 03 - 숫자 세계로 떠난 자연어 上 (1) | 2024.03.27 |