
cb
[Do It! 자연어 처리] Chapter 03 - 숫자 세계로 떠난 자연어 下 본문
본 게시물은 <Do It! BERT와 GPT로 배우는 자연어 처리>의 3장을 보고 정리한 글입니다. 실습에서 사용되는 오픈소스 패키지는 아래의 링크를 참고하시길 바랍니다.
https://github.com/ratsgo/ratsnlp
GitHub - ratsgo/ratsnlp: tools for Natural Language Processing
tools for Natural Language Processing. Contribute to ratsgo/ratsnlp development by creating an account on GitHub.
github.com
트랜스포머가 무엇인지, 어텐션 기법이 무엇인지에 대해서는 이전 포스팅에서 다뤄 보았으니 자세한 설명은 생략하도록 하겠다.
피드포워드 뉴럴 네트워크 (feed forward neural network)
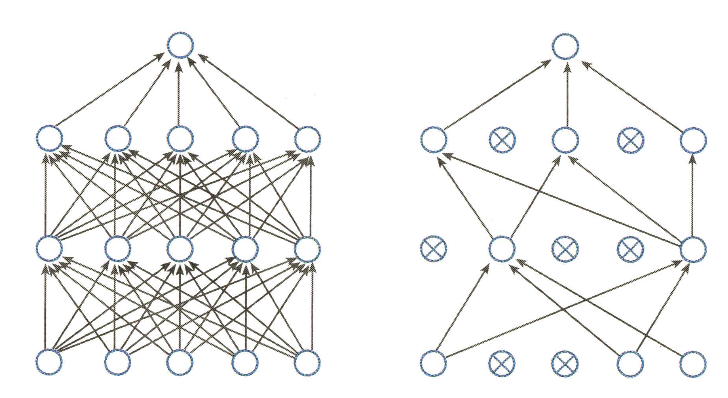
피드 포워드 뉴럴 네트워크는 신경망(neural network)의 한 종류이다. 이는 입력층, 은닉층, 출력층의 총 3개 계층으로 구성되어 있다. 아래 그림에서의 각 동그라미를 뉴런(neuron)이라고 한다.

뉴런은 이전 뉴런값과 그에 해당하는 가중치를 가중합한 결과에 바이어스를 더해 만든다. 활성 함수(activation function)는 현재 계산하고 있는 뉴런의 출력을 일정 범위로 제한하는 역할을 한다.
트랜스포머에서 사용하는 활성 함수는 ReLU(rectified linear unit)이다. 이는 양수 입력에 대해서는 그대로 흘려보내지만 음수 입력은 모두 0으로 치환해 무시한다. 그래프의 개형은 아래와 같다.

잔차 연결(residual connection)
잔차 연결이란 블록이나 레이어 계산을 건너뛰는 경로를 하나 두는 것을 말한다. 입력을 x, 이번 계산 대상 블록을 F라고 할 때 잔차연결은F(x) + x로 실현할 수 있다.

블록 계산이 계속될 때 잔차 연결을 둔다면 아래 그림과 같이 모델의 계산 경로가 여러 가지가 된다. 이는 곧 모델이 다양한 관점에서 블록 계싼을 수행하게 된다는 이야기와도 같다.

딥러닝 모델은 레이어가 많아지면 학습이 어려운 경향이 있다. 모델을 업데이트하기 위한 신호가 전달되는 경로가 길어지기 때문이다. 잔차 연결은 모델 중간에 블록을 건너뛰는 경로를 설정함으로써 학습을 쉽게 하는 효과까지 거둘 수 있다.
레이어 정규화(layer normalization)
레이어 정규화란 미니배치의 인스턴스별로 평균을 빼 주고 표준편차로 나눠 정규화를 수행하는 기법이다. 이는 학습이 안정되고 속도가 빨라지는 등의 효과가 있다.
레이어 정규화는 미니배치의 인스턴스별로 수행한다. 예를 들어, 아래의 배치 크기가 2인 경우 배치의 첫 번째 데이터의 평균과 표준편차가 각각 2, 0.8164이기 때문에 이 값들을 바탕으로 정규화 수식을 계산하게 된다.

드롭아웃(dropout)
딥러닝 모델은 표현력이 아주 좋아서 학습 데이터를 모두 외워버릴 염려가 있다. 이를 과적합(overfitting)이라고 하는데, 드롭아웃은 과적합을 방지하고자 뉴런의 일부를 확률적으로 0으로 대치하여 계산에서 제외하는 기법이다.
아담 옵티마이저
딥러닝 모델 학습은 모델 출력과 정답 사이의 오차(error)를 최소화하는 방향을 구하고 이 방향에 맞춰 모델 전체의 파라미터(parameter)들을 업데이트한다. 이때 오차를 손실(loss), 오차를 최소화하는 방향을 그레이디언트(gradient), 오차를 최소화하는 과정을 최적화(optimization)라고 한다.

우선 오차를 구하기 위해서는 현재 시점의 모델에 입력을 넣어서 처음부터 끝까지 계산해 보고 정답과 비교해 보는 과정을 거쳐야 한다. 이처럼 오차를 구하려고 모델의 처음부터 끝까지 순서대로 계산해 보는 과정을 순전파(forward propagation)라고 한다.
오차를 구한 뒤에는 미분을 통해 오차를 최소화하는 그레이디언트를 구할 수 있다. 미분의 연쇄 법칙(chain rule)에 따라 파라미터별 그레이디언트 역시 구할 수 있다. 이 과정은 순전파의 역순으로 순차적으로 수행되는데, 이 과정을 역전파(back propagation)라고 한다.
아담 옵티마이저는 모델 파라미터 업데이트의 방향과 보폭을 적절하게 정해 주는 역할을 한다. 방향을 정할 때에는 현재 위치에서 경사가 가장 급한 쪽으로 내려가되, 여태까지 내려오던 관성을 일부 유지하도록 한다. 보폭의 경우 안 가본 곳은 성큼 빠르게 걸어 훑고, 많이 가본 곳은 갈수록 보폭을 줄여 세밀하게 탐색하는 방식으로 정한다.
최초의 보폭, 즉 러닝 레이트(learning rate)를 정해 주면 아담 옵티마이저가 최적화 대상 파라미터들에 대상과 보폭을 정해 준다.
BERT와 GPT의 비교
GPT는 언어 모델이다. GPT는 이전 단어들이 주어졌을 때 다음 단어가 무엇인지 맞히는 과정에서 프리트레인한다. 이는 문장의 왼쪽에서 오른쪽으로 순차적으로 계산한다는 점에서 단방향 성격을 가진다.
BERT는 마스크 언어 모델이다. 문장 중간에 빈칸을 만들고 해당 빈칸에 어떤 단어가 적절할기 맞히는 과정에서 프리트레인한다. 빈칸 앞뒤 문맥을 모두 살필 수 있다는 점에서 양방향 성격을 가진다.

GPT는 트랜스포머에서 인코더를 제외하고 디코더만 사용한다. 그림을 자세히 보면 인코더 쪽에서 보내오는 정보를 받는 모듈이 제거되어 있는 것을 확인할 수 있다.
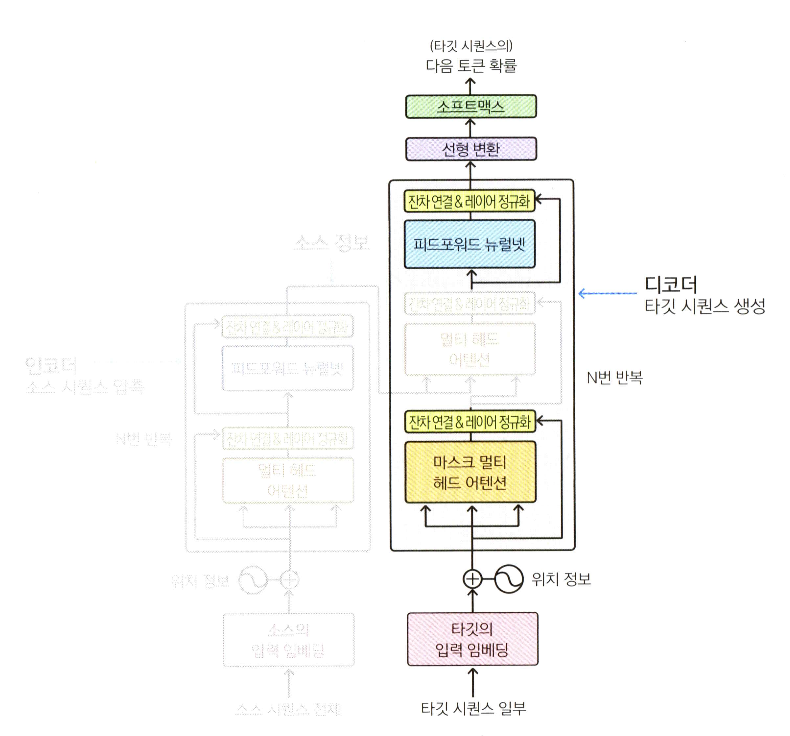
BERT는 트랜스포머에서 디코더를 제외하고 인코더만 사용한다.

파인튜닝(fine tuning)
프리트레인을 마친 모델 위에 작은 모듈을 더 쌓아 다운스트림 데이터로 업데이트하는 과정을 파인튜닝이라고 한다. BERT는 프리트레인을 마친 모델 위에 작은 모듈을 조금 더 쌓아 문서 분류, 개체명 인식 등의 태스크를 수행할 수 있다.
먼저, 문서 분류를 수행하는 모델을 만든다고 하면 아래 그림과 같은 모양이 된다.

그림에서 노란색 박스가 BERT 모델을 의미한다. 모델은 이미 빈칸 맞히기로 프리트레인을 끝마친 상태이다. 기존의 BERT 모델이 동작하는 것처럼 문장 시퀀스를 입력받아 토큰화한 후 모델을 거쳐 문장 벡터를 출력한다.
여기서 파인튜닝은 최종 출력 위에 작은 모듈을 하나 추가해 그 출력이 미리 정해 놓은 범주가 될 확률이 되도록 학습한다. (사진에서의 예시로는 부정, 긍정, 중립 등)
다음으로, 개체명 인식을 수행하는 모델은 아래 그림과 같은 모양이 된다.

개체명 인식에서는 마지막 블록의 모든 단어 벡터를 활용한다. 이는 문서 분류 때와 같은 방식으로 입력값을 만들고 마지막 블록의 출력으로 문장 내 모든 단어의 벡터 시퀀스를 추출한다.
파인튜닝에서는 이렇게 뽑은 단어 벡터들 위에 작은 모듈을 추가하여 그 출력이 각 개체명 범주(기관명, 인명, 지명 등)가 될 확률이 되도록 한다.
'ai - study' 카테고리의 다른 글
| [Do It! 자연어 처리] Chapter 05 - 문장 쌍 분류하기 (0) | 2024.04.08 |
|---|---|
| [Do It! 자연어 처리] Chapter 04 - 문서에 꼬리표 달기 (0) | 2024.04.03 |
| [Do It! 자연어 처리] Chapter 03 - 숫자 세계로 떠난 자연어 上 (1) | 2024.03.27 |
| [Do It! 자연어 처리] Chapter 02 - 문장을 작은 단위로 쪼개기 (3) | 2024.03.18 |
| [Do It! 자연어 처리] Chapter 01 - 처음 만나는 자연어 처리 (0) | 2024.03.13 |



