
cb
[논문 리뷰] Pixel RNN, Pixel CNN 논문리뷰 본문
Pixel Recurrent Neural Networks
Aaron van den Oord, Nal Kalchbrenner, Koray Kavukcuoglu
Pixel Recurrent Neural Networks
Modeling the distribution of natural images is a landmark problem in unsupervised learning. This task requires an image model that is at once expressive, tractable and scalable. We present a deep neural network that sequentially predicts the pixels in an i
arxiv.org
0. Abstract
자연 이미지의 분포를 모델링하는 것은 비지도 학습의 획기적인 문제이다.
본 논문에서는 두 개의 공간 차원을 따라 이미지의 픽셀을 순차적으로 예측하는 심층 신경망을 제안한다. 이 방법은 원본 픽셀 값의 이산 확률을 모델링하고 이미지의 전체 종속성 세트를 인코딩한다. 아키텍처에서는 빠른 2차원 순환 신경망과 깊은 순환 네트워크의 잔차 연결을 효과적으로 사용한다. 이는 자연 이미지에 대한 훨씬 더 나은 log-likelihood score를 달성하였다.
1. Introduction
생성적 이미지 모델링은 비지도 학습의 핵심 문제이다. 확률 밀도 모델은 이미지 압축, inpainiting, deblurring과 같은 이미지 생성에 이용될 수 있다. Generative modeling은 학습할 수 있는 이미지 데이터의 양이 무한하다는 장점이 있다. 그러나 이미지의 고차원성과 구조 때문에 natural image의 분포를 추정하는 것은 매우 어렵다.
PixelRNN은 이미지의 각 픽셀을 예측하기 위해 이전 픽셀들을 모두 고려한다. 이는 Row LSTM, Diagonal BiLSTM이라는 두 가지 종류의 순환 레이어를 사용하여 예측을 진행한다. 먼저 Row LSTM은 이전 픽셀들의 정보를 수직 방향으로 전달하고, Diagonal BiLSTM은 이전 픽셀들의 정보를 대각선 방향으로 전달한다.
PixelRNN은 최대 12개의 빠른 2D LSTM 레이어로 구성되며, state에서 LSTM 단위를 사용한 다음 하나의 공간 차원을 따라 모든 state를 한 번에 계산하기 위해 컨볼루션을 적용한다. 하지만 RowLSTM과 Diagonal BiLSTM은 왼->오의 가로 방향으로만 conv를 적용하여 세로방향에서는 서로 영향을 주고 받지 못 한다는 단점이 있다.
따라서 해당 논문에서는 RNN이 아닌 CNN 아키텍처를 사용하여 레이어 전체에서 입력의 공간 해상도를 보존하고자 하였다. PixelCNN은 PixelRNN과 동일한 핵심 구성 요소를 공유하지만, Masked convolution을 사용하여 고정된 종속성을 가진 시퀀스 모델로도 사용된다. PixelCNN은 15개 레이어로 구성된 fully convolutional network 아키텍처를 가진다.
PixelRNN과 PixelCNN은 독립 과정(like latent variable models)을 도입하지 않고 픽셀 상호 의존성을 나타낸다. 종속성은 각 픽셀 내의 RGB 색상 값 간에도 유지된다. 또한 픽셀을 연속 값으로 모델링하는 이전 접근 방식과 달리 간단한 softmax layer로 구현된 다항 분포를 사용하여 픽셀을 이산 값으로 모델링한다. 이 접근 방식은 모델에 대한 표현과 학습에 대한 advantage를 제공한다.
2. Model
2.0 Generating an Image Pixel by Pixel

우선, 목표는 n×n 픽셀로 구성된 각 이미지 x에 확률 p(x)를 할당하는 것이다. 이미지 x를 1차원 시퀀스 x1, ..., xn2라 할 때, 결합 분포 p(x)는 위와 같이 작성될 수 있다. 값 p(xi|x1, ..., xi−1)은 모든 이전 픽셀 x1, ..., xi−1이 주어졌을 때 i번째 픽셀 xi의 조건부 확률을 의미한다. 이는 즉 이전까지 만들어낸 픽셀값들을 바탕으로 현재 픽셀값을 예측해간다고 이해할 수 있다.
위 그림을 보면 컨디셔닝 방식을 더욱 쉽게 이해할 수 있다. 처음 Grayscale 이미지를 샘플할 때에는 단순 샘플링만 진행한다. 그러나 각 픽셀 xi는 한 가지 색상이 아닌, 빨간색, 녹색, 파란색의 RGB 채널에 대해 공동으로 결정된다. 첫 번째 과정에서 R, G, B 각각의 픽셀들을 계산하고 각각의 R, G, B 안에서 또 계산을 진행한다.
분포 p(xi|x<i)를 위의 식으로 다시 작성하면, 각 색상 채널에서는 이전에 생성된 모든 픽셀뿐만 아니라 다른 채널에서 생성된 값들까지 참고한다는 것을 알 수 있다.
2.1 RowLSTM
Row LSTM은 전체 행에 대한 컴퓨팅 기능을 위에서 아래로 한 행씩 처리하는 단방향 레이어이다. 계산은 1차원 컨볼루션으로 수행된다.(1차원 컨볼루션의 커널은 크기 k × 1을 가지며, 여기서 k ≥ 3이다. 당연히 k 값이 클수록 캡처되는 컨텍스트가 더 넓어진다.)
그림에서 위의 부분은 hidden state이고 아래 부분은 initial state이다. Row LSTM은 여기서 3개의 hidden state를 참고하기 때문에, 파란색의 initial state 하나를 만들기 위해서는 픽셀 위의 삼각형 범위의 컨텍스트를 캡처하는 셈이 된다.
하지만 이러한 방식으로 계산을 진행하게 된다면, 삼각형의 receptive field만을 가지기 때문에 전체 컨텍스트를 참고하지 못한다는 단점이 존재한다.
2.2 Diagonal BiLSTM
이러한 문제를 해결하기 위해 나온 것이 Diagonal BiLSTM이다.
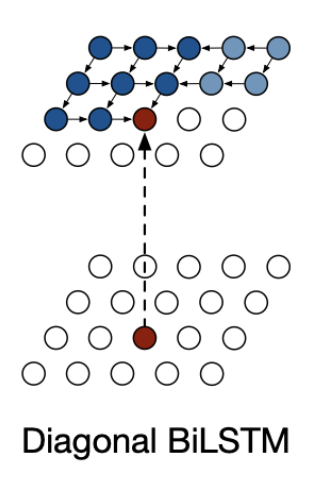
Diagonal BiLSTM은 모든 이미지에 대해 사용 가능한 전체 컨텍스트를 캡처하도록 설계되었다. 레이어는 위쪽 모서리에서 시작하여 아래쪽 반대쪽 모서리에 도달하는 대각선 방식으로 이미지를 스캔한다. 계산의 각 단계는 이미지의 대각선을 따라 LSTM 상태를 한 번에 계산한다.
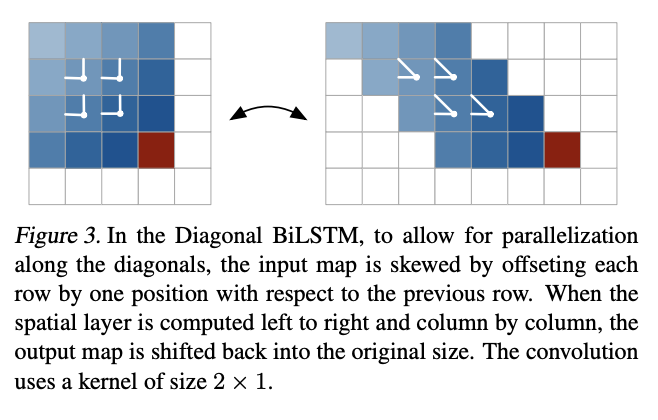
대각선 계산은 다음과 같이 진행된다. 먼저 입력 맵을 대각선을 따라 컨볼루션을 쉽게 적용할 수 있는 공간으로 shifting한다. skewing 작업은 그림 3에 표시된 것처럼 입력 맵의 각 행을 이전 행에 대해 한 위치만큼 오프셋한다. 이 시점에서 Diagonal BiLSTM의 입력-상태 및 상태-상태 구성요소를 계산할 수 있다.
이 단계는 이전 은닉 상태와 셀 상태를 취하고 입력-상태 구성 요소의 기여도를 결합하여 다음 은닉 상태와 셀 상태를 생성한다. 그런 다음 오프셋 위치를 제거하여 기능 맵을 n × n 맵으로 다시 기울인다. 이 계산은 왼쪽 위, 오른쪽 위 양쪽 모두에 대해 반복된다. 그렇기 때문에 양쪽의 패턴을 모두 참고할 수 있고, 결과적으로 전체 컨텍스트를 모두 담을 수 있다.
2.3.1 PixelCNN
하지만 각각의 픽셀에 대해 모든 계산을 순차적으로 진행하게 되면, 계산량이 매우 커 복잡해진다는 단점이 존재한다. 따라서 본 논문에서는 아예 컨볼루션을 적용해 계산을 수행하는 PixelCNN도 제안하였다.
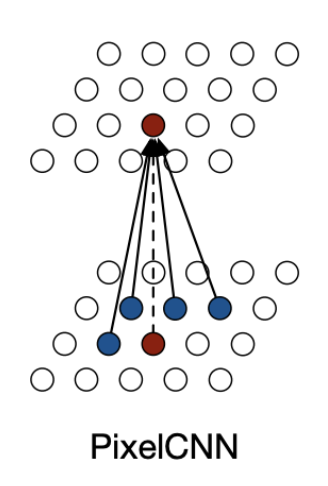
표준 컨볼루셔널 레이어를 사용한다면모든 픽셀 위치에 대한 특징을 한 번에 계산할 수 있다. PixelCNN은 공간 해상도를 유지하는 여러 컨볼루셔널 레이어를 사용한다. 풀링 레이어는 사용되지 않았다.
샘플링된 각 픽셀은 네트워크에 다시 입력으로 제공되어야 하기 때문에, 이미지 생성 프로세스는 두 종류의 네트워크 모두에 대해 순차적으로 이루어진다. 여기서 Pixel CNN은 미래에 만들어질 context를 이전에 참고하지 않기 위해 마스킹을 사용하였다.
2.3.2 Masked convolution

위의 표에서도 알 수 있듯이 마스킹 과정에서는 두 가지 방법이 사용되었다.
우선, mask A는 PixelRNN의 첫 번째 컨벌루션 레이어에만 적용된다. 이는 인접한 픽셀과 이미 예측된 현재 픽셀의 색상에 대한 연결을 제한다.
반면 mask B는 모든 후속 입력-상태 컨벌루션 전이(subsequent input-to-state convolutional transitions)에 적용되며 색상 자체로의 연결도 허용하기 때문에 mask A의 제한을 완화할 수 있다.
3. Experiments

4. Conclusion
본 논문에서는 자연 이미지의 생성 모델로서 심층 순환 신경망을 크게 개선하고 구축했다. 더 큰 데이터세트로 더 쉽게 확장할 수 있는 새로운 2차원 LSTM 레이어인 Row LSTM과 Diagonal BiLSTM을 설명했다. 모델은 원시 RGB 픽셀 값을 모델링하도록 훈련되었다. 조건부 분포에서 소프트맥스 레이어를 사용하여 픽셀 값을 이산 확률 변수로 처리했다. 우리는 PixelRNN이 색상 채널 간의 완전한 종속성을 모델링할 수 있도록 마스크된 컨볼루션을 사용했다.
또, PixelRNN이 MNIST 및 CIFAR-10 데이터 세트의 최신 기술을 크게 향상시키는 것을 보여주었다. ImageNet 데이터세트의 생성 이미지 모델링을 위한 새로운 벤치마크도 제공한다. 이러한 모델을 더 크게 만들수록 개선되고 훈련할 수 있는 데이터가 실질적으로 무제한이라는 점을 고려하면 더 많은 계산과 더 큰 모델을 사용하면 결과가 더욱 향상될 가능성이 높다고 한다.
'ai - paper' 카테고리의 다른 글
| [모델 정리] 딥러닝 논문리뷰 및 정리 II (0) | 2024.05.07 |
|---|---|
| [모델 정리] 딥러닝 논문리뷰 및 정리 I (0) | 2024.05.07 |
| [논문리뷰] Transformer 논문 리뷰 (0) | 2023.08.23 |
| [논문 리뷰] BERT 논문 리뷰 (0) | 2023.08.23 |
| [논문 리뷰] GAN 논문리뷰 (0) | 2023.08.09 |


